
…Critical evaluation of some use cases
Technology is fast changing how industries operate today. The fast-paced innovations and their consequent applications in industry have led to a more rapid advancement in the operations, strategy, and management of these industries. The law sector has not been spared by the ravaging fire of technological innovations fast changing the playing fields of industries. It has introduced new regimes of data-driven decision making, legal analytics, prescriptive forecasting, and contract reviews, due diligence, automated client advisory services amidst a myriad of other use cases within the legal sphere. This has led to efficiency improvements, increased profitability, and quality improvements amongst others in the delivery of legal services to prospective clients. Critical to these improvements is Artificial Intelligence.
Marvin Minsky, in the MIT publication on Semantic Information processing, described Artificial intelligence as the science of making machines do that which would require intelligence if done by men. Thus, Artificial Intelligence (AI) seeks to enable machines to perform or act roles likable to humans. Others have also defined AI as a ‘big forest of academic and commercial work around the science and engineering of making intelligent machines, a combined definition by John McCarthy, who coined the term Artificial Intelligence and with the expertise of Michael Mills. The term AI is broadly used as an umbrella term to include all areas of technology with such applicability. It includes the fields of machine learning, natural language processing (NLP), expert systems, visions, speech, planning and robotics. However, as at today, just a few areas of AI are applicable to legal services and Law, namely machine learning, Natural language processing and expert systems.
The diagram below shows the various field of AI and their subbranches.
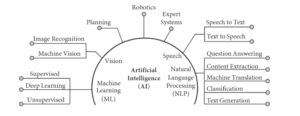
I will discuss how AI-powered solutions could be utilised to promote efficiency when resourcing is not an issue as well as which automation solutions could be adapted in conditions of limited resources. As stated above, the use of AI in law or delivery of legal services revolves around the fields of Machine Learning, Natural Language Processing, and Expert Systems. I will therefore discuss in depth, these technologies in their technical sense in general before I proceed to discuss the specific AI-powered solutions and their usage of these fields of AI technologies. These AI-powered solutions though proprietary rely on these technologies to design the base algorithms that resolve all queries fed into them within the legal service delivery space for insights, predictive outcomes, or analytics.
Artificial Intelligence has two approaches, namely, Rule Based approach and Learning Based approach. Rule Based AI systems utilize the use of a set of human-coded rules that output some pre-determined outcomes. Thus, it follows the ‘if-then’ coding statements format, thus if a specific action is executed, a certain desired output is required. Of importance to this approach to the developers are “a set of rules” and “a set of facts”, from which an intelligence model can be created. This framework approach makes the model immutable in its structure and unscalable in its application, as it can only perform specific assignments or tasks as programmed based on the set of rules and facts. Rhett D’Souza, in his article titled, “Symbolic AI vs. Non Symbolic AI, and everything between them”?, referred to it as Symbolic Artificial Intelligence, also known as Good Old Fashioned AI (GOFAI), which makes use of strings that represent real-world entities or concepts, that are stored manually or incrementally in a Knowledge Base (any appropriate data structure) and made available to the interfacing human being/machine as and when requested, as well as used to make intelligent conclusions and decisions based on the memorized facts and rules put together by propositional logic or first-order predicate calculus techniques. They are largely used in Expert / Knowledge systems, Contract builders and Chabot. It is critical to mention that for rule-based AI’s systems in law, a domain expert (a lawyer); a knowledge engineer and an end user are the key players.
The requirement of a domain expert is vital as based on the domain expert’s knowledge; rules will be curated based on facts to be applied to by the system to resolve a problem. It applies the principles of forward and backward chaining to answer what and why questions/problem, by referring to the knowledge base that contains information on the problem categories, usually from a repository of collated information from various domain experts. These knowledge bases are either factual or heuristic knowledge. It arguably gives a higher sense of level of competence, as well as accuracy and efficiency.
Machine learning is a form of AI that enables a system to learn from data rather than through explicit programming. Unlike Rule Based AI systems that rely on sets of facts and rules to solve a problem presented to it, Machine learning, which is a non-symbolic AI approach relies on the volumes of big data presented it, to learn itself and relearning necessary. It does iterative learnings from the big data set available to it, to improve itself and predict future outcomes. In its early stages, it trains itself from the enormous, big data available to form precise models based on the data. At the end of the training of the machine with the data, a machine learning model is designed that can take an input and based on the train model, provide an output. A typical example is the suggestive products of similar kind from websites after searching for some specific products. This they achieve via training the browsing history of a huge number of users as well as their purchasing data to make these suggestions to you. It is vital to note that these learnings of the data could be online or offline. With regards to the offline learning models, the models do not change real time. However, for the online learning models, the models change real time and continuously improves itself as new data is being fed to it, thus, it learns and re-learns itself to become better. The more the data, the more the near perfection of the model. Big data refers to generally, the large volumes of data with diverse sources of this data. The more the extreme volumes of data, the more accurate the model being trained.
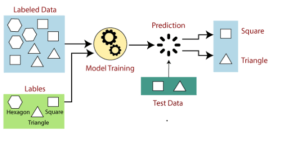
Machine learning has three (3) subcategories namely supervised learning, unsupervised learning, and deep learning. In Supervised learning, the machines are trained using labelled data. Thus, via a set of established data, the machine learns itself and form patterns that could be applicable to an analytic process. Various categories of similar labelled data are established and used to train, based on the attributes of the labelled. Thus, supervised learning is a process of providing input data as well as correct output data to the machine learning model. The aim of a supervised learning algorithm is to find a mapping function to map the input variable(x) with the output variable(y). The labelled data maybe continuous, thus regressional or from a finite set of values described as classification. Using some examples, the algorithms are trained and later tested with a test data to help identify patterns within the subset that usually may be difficult to be seen within a large, big data. A model is over-fitting if it’s tuned for a particular training data and not applicable for any group of larger sets of unknown data. The accuracy of a model for its predictive outcomes may be ascertained by using unforeseen data for the test set.
Unsupervised learning on the other hand, is applicable in problems with extremely large volumes of unlabelled data. It therefore makes use of algorithms capable of understanding these huge volumes of data sets and classifies them with respect to the patterns or clusters it finds, creating labels so they become supervised. This type of machine learning is primarily focused on clustering, a means of assembling similar object /data points as a grouping and those which are dissimilar in other clusters. Mostly used algorithms are k-means clustering algorithms and fuzzy k-means algorithms. Reinforced learning differs from the above as its not trained with sample data set, but through trial and error, it learns and after some series of positive decisions, it reinforces the process. Similar algorithm is used in self –driving cars.
Bernard Marr, in his article titled ‘What Is Deep Learning AI,’ defined Deep Learning as a subset of machine learning where artificial neural networks, algorithms inspired by the human brain, learn from large amounts of data. The name deep learning stems from the fact that the neural networks have deep layers which enables its learning’s of data sets of diverse, unstructured, and inter-connected nature. Tasks are repeatedly executed, and its outcome tweaked to improve the outcome. It is estimated that over 2.6 quintillion bytes of big data are generated daily. This serves as a good resource unstructured, deep learning algorithms to learn the data.
In the next article, I will continue to discuss in depth, these technologies in their technical sense in general.
The writer is a Member, Institute of ICT Professionals Ghana
For comments, contact author [email protected]








